
For the Informs Analytics Conference attendees
Informs poster (click for high-resolution PDF)
Project Overview
This is an experimental, but highly accurate, two-dimensional (currently) clustering algorithm based upon Delaunay Triangulation. Triangulation Clustering out-performs (on average) even the best standard clustering algorithms when tested against the scikit-learn benchmark suite.
Approach

| Given this set of datapoints, |
 |
a Delaunay Triangulation is performed, which subdivides the space into triangles whose circumcirlces do not contain any points that are not a part of that triangle. This approach maximizes th. size of the smallest angle, which helps avoid triangles with excessively thin (two acute angles) triangles. |
 |
Triangles are progressively removed by eliminating triangles whose perimeters are significantly greater than the average of the triangles connected to any point (see the animation below) |
 |
Once the culling has completed, the still-connected triangle meshes are grouped into unique clusters. |
Mismatched Triangle Culling
Performance
Performance of the Triangulation Clustering was compared to the following standard clustering algorithms using datasets in the sci-kit clustering benchmark:- Affinity Propagation
- Average (Hierarchical)
- Birch
- Centroid
- DBSCAN
- Mean Shift
- Spectral Clustering
- Ward (Hierarchical)
All algorithms except for Centroid are sourced from the Python-based scikit-learn library. The Centroid algorithm was tested using SAS®.
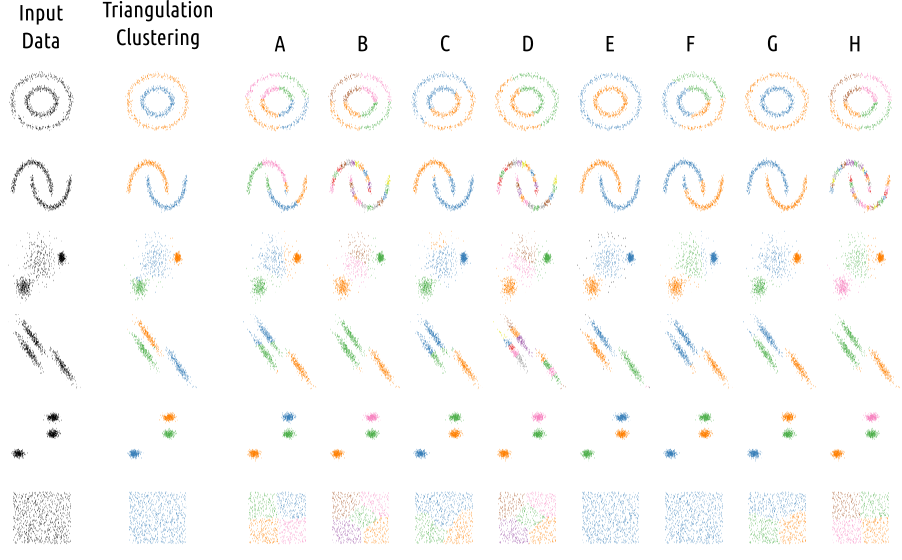
The performance of each algorithm operating on each dataset is computed using Adjusted Mutual Information Scoring, which is a function that measures the agreement of two assignments whilst ignoring permutations.
As can be seen in the following table, the Triangulation Clustering had the best overall performance and performed poorly on none of the datasets.
| TC | A | B | C | D | E | F | G | H | |
|---|---|---|---|---|---|---|---|---|---|
| Noisy Circles | 0.993 | -0.001 | -0.001 | 0.004 | 0.000 | 1.000 | 0.006 | 1.000 | -0.001 |
| Noisy Moons | 1.000 | 0.356 | 0.353 | 0.599 | 0.353 | 1.000 | 0.440 | 1.000 | 0.317 |
| Varied | 0.821 | 0.801 | 0.785 | 0.655 | 0.785 | 0.664 | 0.825 | 0.915 | 0.813 |
| Aniso | 0.956 | 0.621 | 0.652 | 0.632 | 0.586 | 0.955 | 0.628 | 0.944 | 0.652 |
| Blobs | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| No Structure | 1.000 | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 |
| Average Score | 0.962 | 0.463 | 0.465 | 0.482 | 0.454 | 0.936 | 0.650 | 0.810 | 0.464 |
Future Work
- As currently implemented, the algorithm only operates on two-dimensional data, which is an obvious limitation. By taking advantage of n-dimensional Delaunay Triangulation implementations, we intend to make this a general-purpose clustering algorithm.
- We intend to rewrite the algorithm in a much higher-performing language such as C++ or Rust and then make the library available as Python package.
- The triangle-culling portion of the algorithm is inherently parallelizable, so significant speedup could be realized by targeting a GPU for that portion of the code.
Conclusions
Performance of the Trianglulation Clustering algorithm exceeded our expectations. Compared against a suite of standard algorithms and on a wide-variety of two-dimensional datasets, Triangulation Clustering scored best overall and performed solidly on every dataset.
Once extended to operate on n-dimensional data, and assuming comparable performance, we will package the algorithm for general distribution as a Python library.